Chapter 5
Software
There are different software solutions for building computer-vision systems. The software for this work encompasses several interdependent parts: image processing and transmission, data processing, and neural networks.
For image processing, several modules are available (OpenCV [36 ], Scikit-Image [37 ], SciPy [38 ], Pillow [39 ]), of which OpenCV and Scikit-Image were built specifically for machine learning. To solve this task, the OpenCV module was used instead of Scikit-Image, because the former also supports reading video via Gstreamer [40 ], which allows use of the Nvidia video decoder [41 ] integrated into the Jetson. This saves the CPU when reading the image stream and does so significantly more efficiently, leaving more headroom on the system’s CPU for image processing and the computer-vision model’s work.
For data processing the Pandas [42 ] module is widely used, providing simple and intuitive commands to analyse and manipulate data. This module performs operations on the CPU, and for extreme data volumes data processing can become time-consuming. In addition to Pandas, several alternative modules have been built that are similarly or marginally better optimised, the closest in operating principle and writing style being cuDF [44 ]. cuDF is essentially most similar to Pandas, but uses the GPU instead of the CPU for data processing, which – especially when handling large data volumes – gives a significant time advantage over Pandas, because processing takes place with much greater parallelism than on the CPU. At the time of writing, the Pandas module is in use, because the thesis author has broader experience working with this module. There are later plans to switch to development with cuDF for the purpose of software optimisation.
For neural networks there are several platforms and frameworks: TensorFlow [45 ], Keras [46 ], PyTorch [47 ], Scikit-Learn [48 ], of which the most popular and widely used are TensorFlow and PyTorch. This work used PyTorch, because compared with TensorFlow, PyTorch’s syntax is more Pythonic, which makes it easier to integrate with Python objects and makes error messages easier to understand. The thesis author also has prior experience developing with PyTorch.
Computer-vision neural network model
There are several models available for object detection, differing from one another in accuracy, input resolution, size, and speed. Choosing a model means accounting for the system’s throughput: more capable systems such as servers can run massive, accurate models in parallel with minimal impact on input-processing speed. Smaller systems such as laptops and embedded systems, by contrast, are better suited to running smaller, faster models.
| Model | Max input (px) | Speed (ms) | Accuracy (mAP) |
| FasterRCNN [49 ] | 1000x600 | 198 | 73.2 (PASCAL VOC 2007) |
| YOLOv5 [50 ] | 1280x1280 | 26.2 (V100 GPU) | 72.7 (MSCOCO) |
| MobileNet SSD V2 [51 ] | 320x320 | 200 (Google Pixel 1) | 22.2 (MSCOCO) |
| EfficientDet [52 ] | 1536x1536 | 153 (V100 GPU) | 55.1 (MSCOCO) |
Overview of the parameters of the most popular models
For this system, the model had to be chosen with the best accuracy-to-speed ratio in mind. The chosen model also had to be capable of processing information from several video inputs at once (see Table 4).
The YOLOv5 architecture network was selected to solve the task; it was built by Ultralytics [53 ] as an evolution of YOLOv4 [54 ] and is faster and more accurate than its predecessors. It is also a compact model that is easy to run on embedded systems. The model operates on the single-pass frame-processing philosophy (You Only Look Once) – the image passes through the network only once (unlike other models), and within that single pass object detection and classification happen together, which is why the model’s detection operation is also faster (see Figure 10).
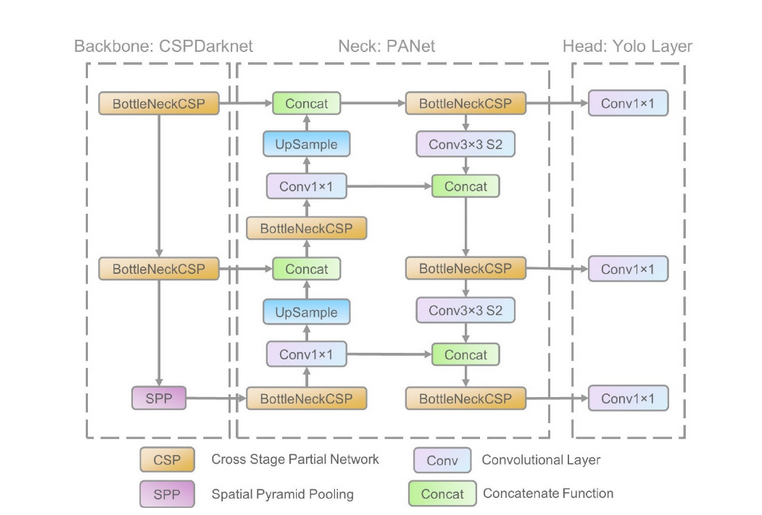
Architecture of the YOLOv5 models [55 ]
The model consists of three parts: backbone, neck, and head.
-
The backbone is the base on which the model is built; here, CSPNet (Cross-Stage Partial Network) was chosen. It is a kind of neural-network model split into several stages (Cross-Stage), in which each layer extracts information from the given image – such as edges and shapes characteristic of the object in the image. Part of the information acquired in earlier layers is passed on to the next layers for processing (Partial), which allows the network to progressively understand what the image depicts better and more accurately, using processed information from the previous layers. The backbone consists mainly of convolutional layers and a downsampling layer, whose output passes on to the model’s neck. A model with this kind of architecture helps reduce the number of computations required.
-
The neck of the neural network is responsible for assembling and organising the information received from the backbone into a feature map, using filters. This model applies a spatial attention pooling method that helps the network focus on important parts of the image, and a Spatial Pyramid Pooling layer, which allows objects to be detected at different resolutions.
-
The head generates the probabilities and coordinates of detections for the objects found in the frame. This model also uses anchor boxes, which are pre-configured with given aspect ratios that help detect objects of different sizes and shapes. The model’s head contains a number of convolutional layers that predict detection coordinates and probabilities for each object [55 ].